Premable
Data engineering is more than just integration - building robust, performant, and documented data-pipelines requires a complete appreciation for the processes that influence and change your product data-sources.
dbt is software package that offers an integrated and modular approach to integration of your static and API-generated data-sources into warehouses such as PostgreSQL, Redshift, and Snowflake.
First class support for data-ingestion, data-modelling, integration into productive systems is offered. Key features include source definition, seeding, snapshots, ephemeral materialization, incremental models, change data capture, macros, and testing.
Deliverable
To probe some of the capabilities of dbt I built a small case-study.
The presented data-analytics pipeline ingests flights data, defines transformations based on business logic, incorporates seeding, snapshots, and uses testing functionality.
The target data-warehouse is a local PostgreSQL database, however any supported DB could have been substituted. A base (“test”) user was given permissions to access the given schemas, and resources on the server.
One core table is used, a file containing 300000+ rows of flights data for airlines operating out of the state of New York in 2013. Note this typically would be tables contained in a core operational DWH system.
dbt Principles
dbt projects are defined using two key components:
- a profile file
profiles.yml - a projects-specific configuration file
dbt_project.yml
The profiles file defines the relationship between a data-warehouse and a project. This essentially maps configuration settings such as target, database, schema, port and user credentials to a given project.
The project-specific configuration file is found in the top-level directory of the project and calls the required profile file, defines project specific settings, and specifies an array of functional settings for steps such as transformations, testing etc.
The standard project directory structure is as follows;
- /analysis
- /data
- /dbt_modules
- /logs
- /macros
- /models
- /snapshots
- /target
- /tests
The most relevant paths for this introduction are data, snapshots, and models.
- Data holds your source tables (.csv files).
- Snapshots holds SQL-statements which can be used to create snapshots of your data-sources using either a “time-stamp” or a “check” strategy.
- The centerpiece is the models directory which stores the SQL-statements that transform your raw data into aggregated views/tables and final analytical products.
Initialization
To initialize a project is a simple as;
dbt initThen one can check the dependencies and configuration profile is correctly defined using;
dbt debug 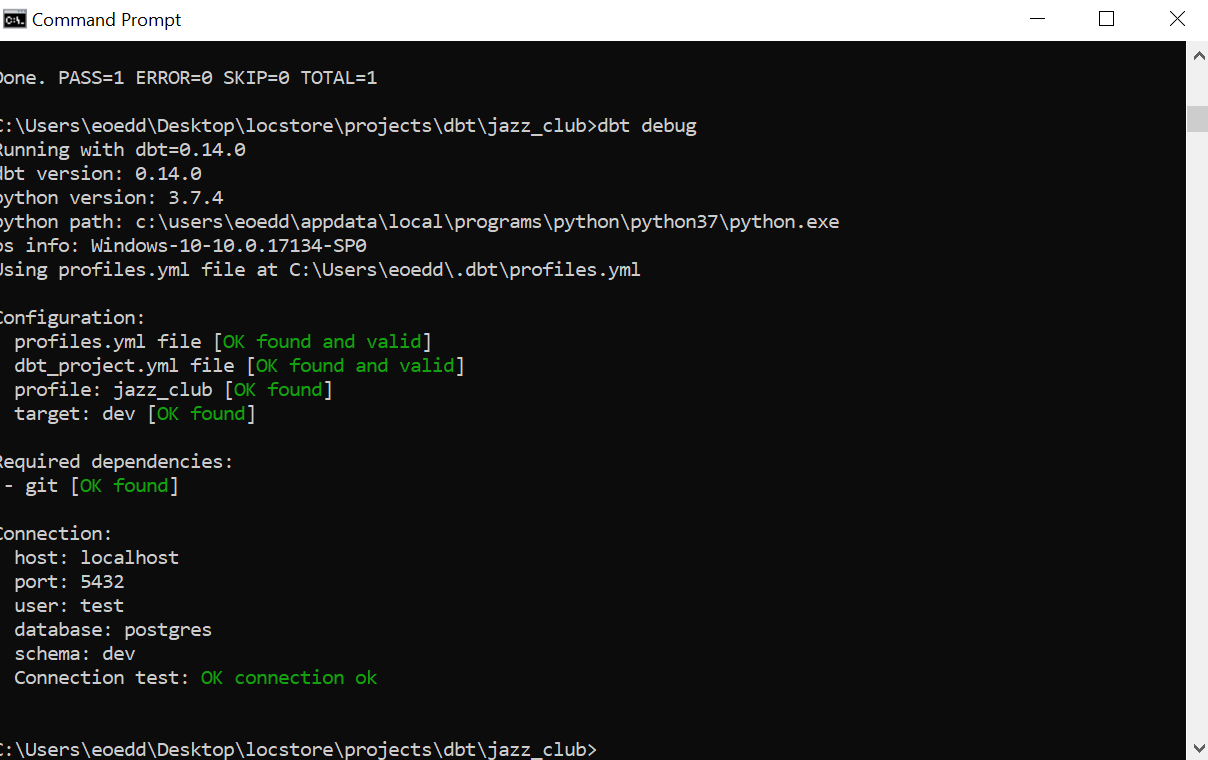
The dbt_projects.yml for this project is shown below;
# Package names should contain only lowercase characters
# and underscores. A good package name should reflect your organization's
# name or the intended use of these models
name: 'jazz_club'
version: '1.0'
# This setting configures which "profile" dbt uses for this project. Profiles contain
# database connection information, and should be configured in the ~/.dbt/profiles.yml file
profile: 'jazz_club'
# These configurations specify where dbt should look for different types of files.
# The `source-paths` config, for example, states that source models can be found
# in the "models/" directory. You probably won't need to change these!
source-paths: ["models"]
analysis-paths: ["analysis"]
test-paths: ["tests"]
data-paths: ["data"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"] # Running `dbt snapshot` will run these snapshots.
target-path: "target" # directory which will store compiled SQL files
clean-targets: # directories to be removed by `dbt clean`
- "target"
- "dbt_modules"
# You can define configurations for models in the `source-paths` directory here.
# Using these configurations, you can enable or disable models, change how they
# are materialized, and more!
# In this example config, we tell dbt to build all models in the example/ directory
# as views (the default). These settings can be overridden in the individual model files
# using the `{{ config(...) }}` macro.
models:
jazz_club:
flights:
materialized: tableAs seen above, many project and model specific settings can be defined from this config file. Customization can be applied here, or in combination with source-level definitions.
Loading Source Tables
Initial data-ingestion is initiated with the dbt seed command.
# truncate and load table as new
# useful for when source schema has altered from orignal format
dbt seed --full-refresh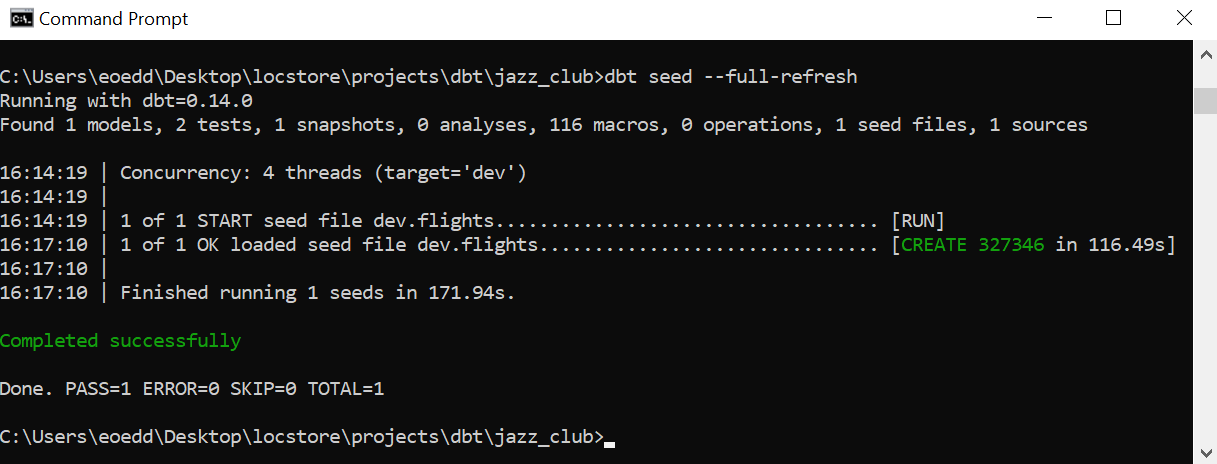
Leveraging Data-Management Features
In this exploratory study I use snapshot functionality to keep track of two columns in the source table.
Alternatively an updated_at column can be supplied for direct monitoring of a well-known column than records update history. See the dbt documentation for more information.
The snapshots are stored in a separate target schema, as defined in the SQL statement saved in /snapshots/check_flights.sql.
dbt snapshot
## sql script "check_flights.sql" defining snapshot method
{% snapshot flight_snapshot_check %}
{{
config(
target_schema='snapshots',
strategy='check',
unique_key='id_',
check_cols=['dep_delay', 'arr_delay'],
)
}}
select * from {{ source('delay', 'flights') }}
{% endsnapshot %}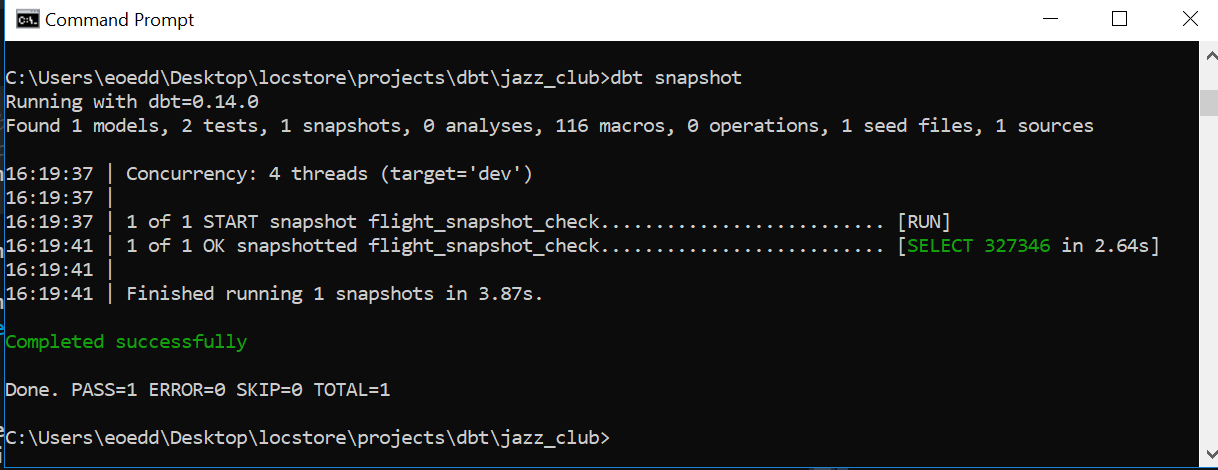
Executing the Analytical Transformations
Data transformations are handled by models in dbt. These models can be arranged in a nested structure per data-source, and they simply call SELECT statements on the referenced tables. Complementary functionality can be added via macros or analyses scripts.
In this example, I produce a simple aggregated table of all flights eligible for delayed boarding compensation. An array of control mechanisms can be passed to the dbt run command to tune which dependencies and models are called.
dbt run
## script "stg_dbc_flights.sql" implementing business logic transformations
with source as (
select * from {{ source('delay', 'flights') }}
where dep_delay > 180
),
renamed as (
select
id_ as flight_id,
year,
month,
day,
dep_time,
carrier,
flight,
origin,
dest
from source
)
select * from renamed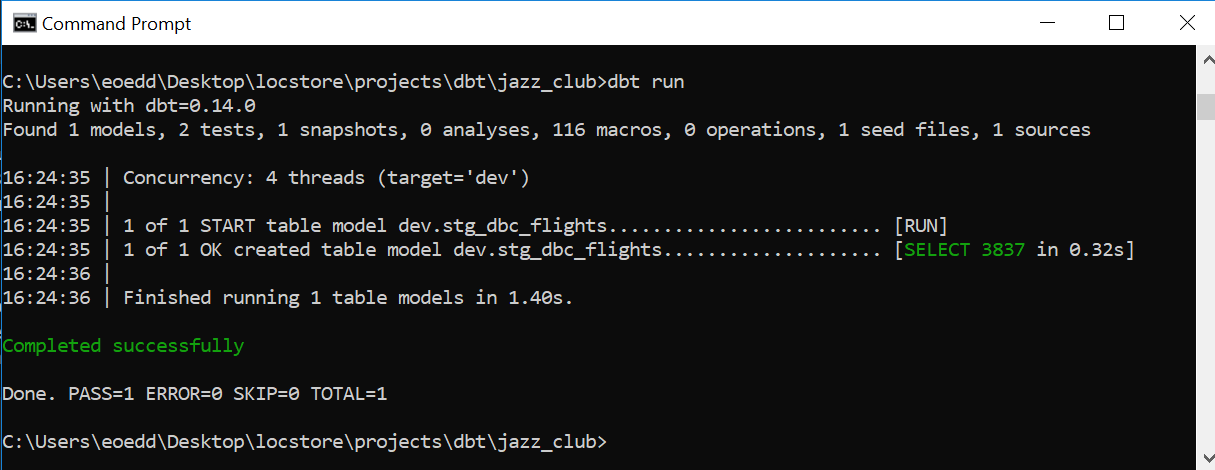
Testing and Integrity Management
Ensuring a consistent and reliable data engineering process requires methods for handling errors. Testing for constraints and data/schema consistency in dbt is defined with schema.yml configuration files. These files are stored in the relevant model directories for data-source specific control.
The criteria specified for this case-study check for uniqueness and non-null constraints on the source data.
# This source entry describes the table:
# "postgres"."dev"."flights"
#
# It can be referenced in model calls with:
# {{ source('delay', 'flights') }}
version: 2
sources:
- name: delay
database: postgres
schema: dev
tables:
- name: flights
models:
- name: stg_dbc_flights
description: The source table contains flights data from state of NY in 2013
columns:
- name: id_
description: This a unique flight identifier for the event
tests:
- unique
- not_null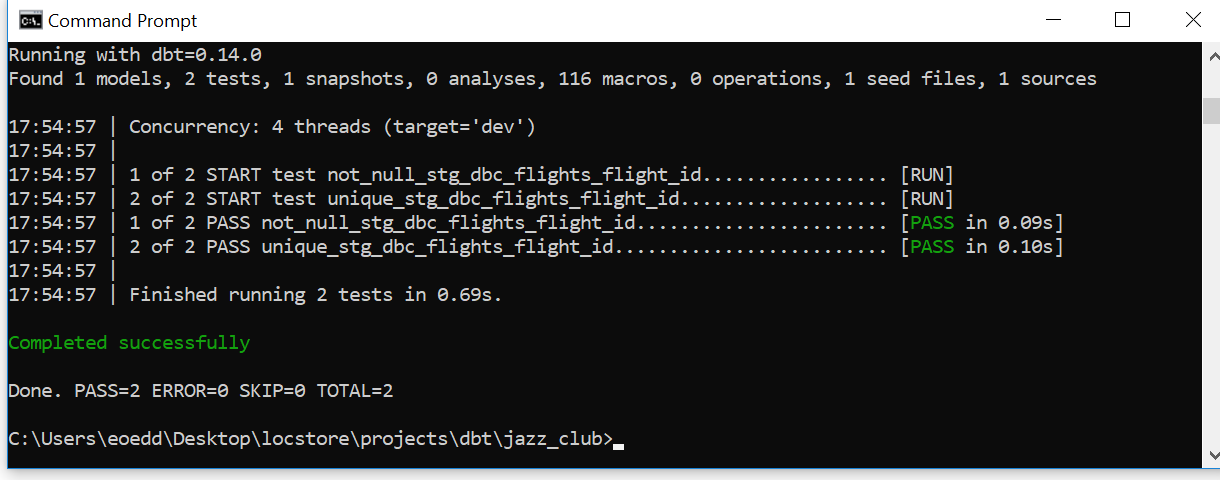
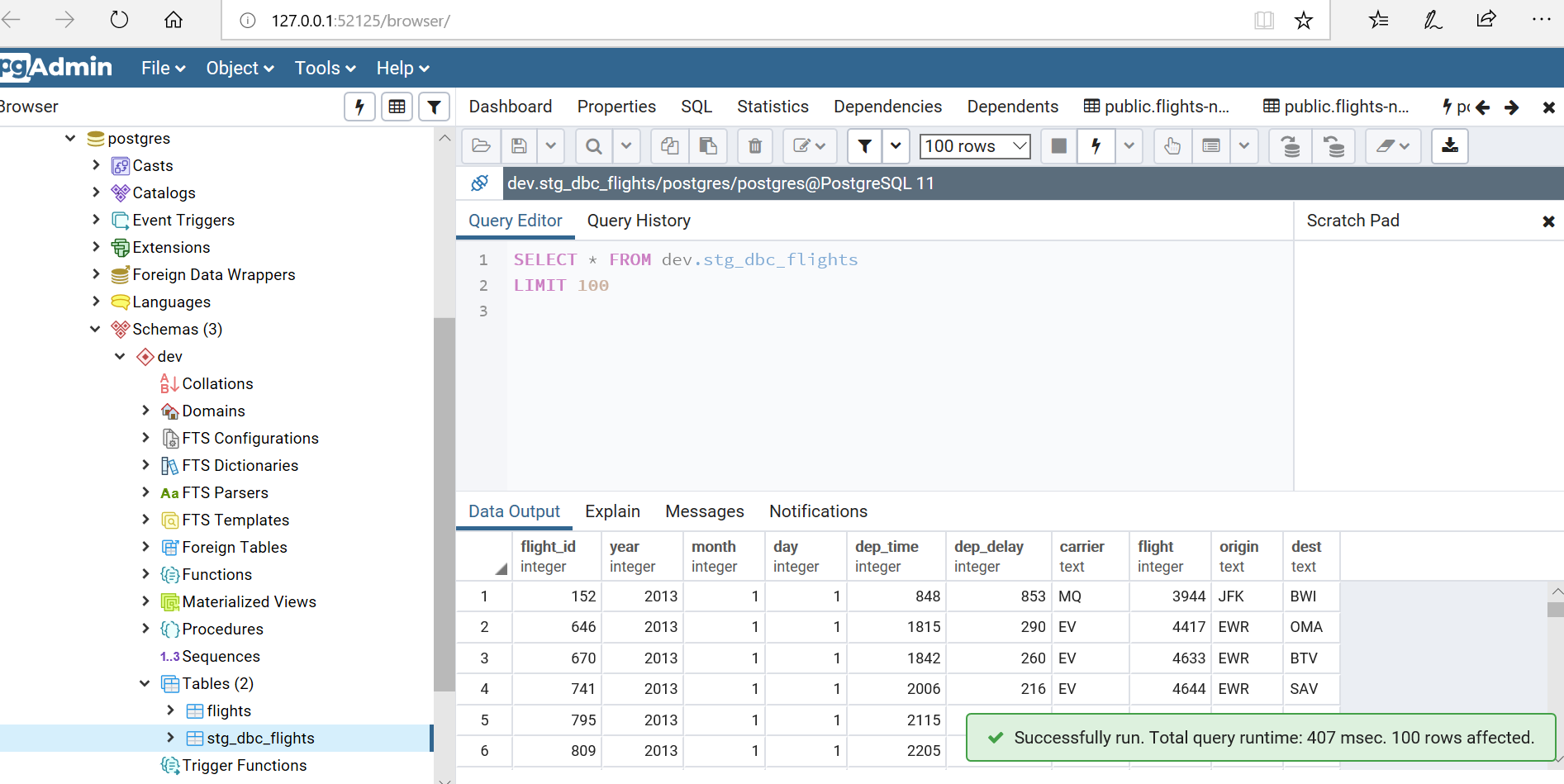
The resulting tables as shown in pgAdmin.