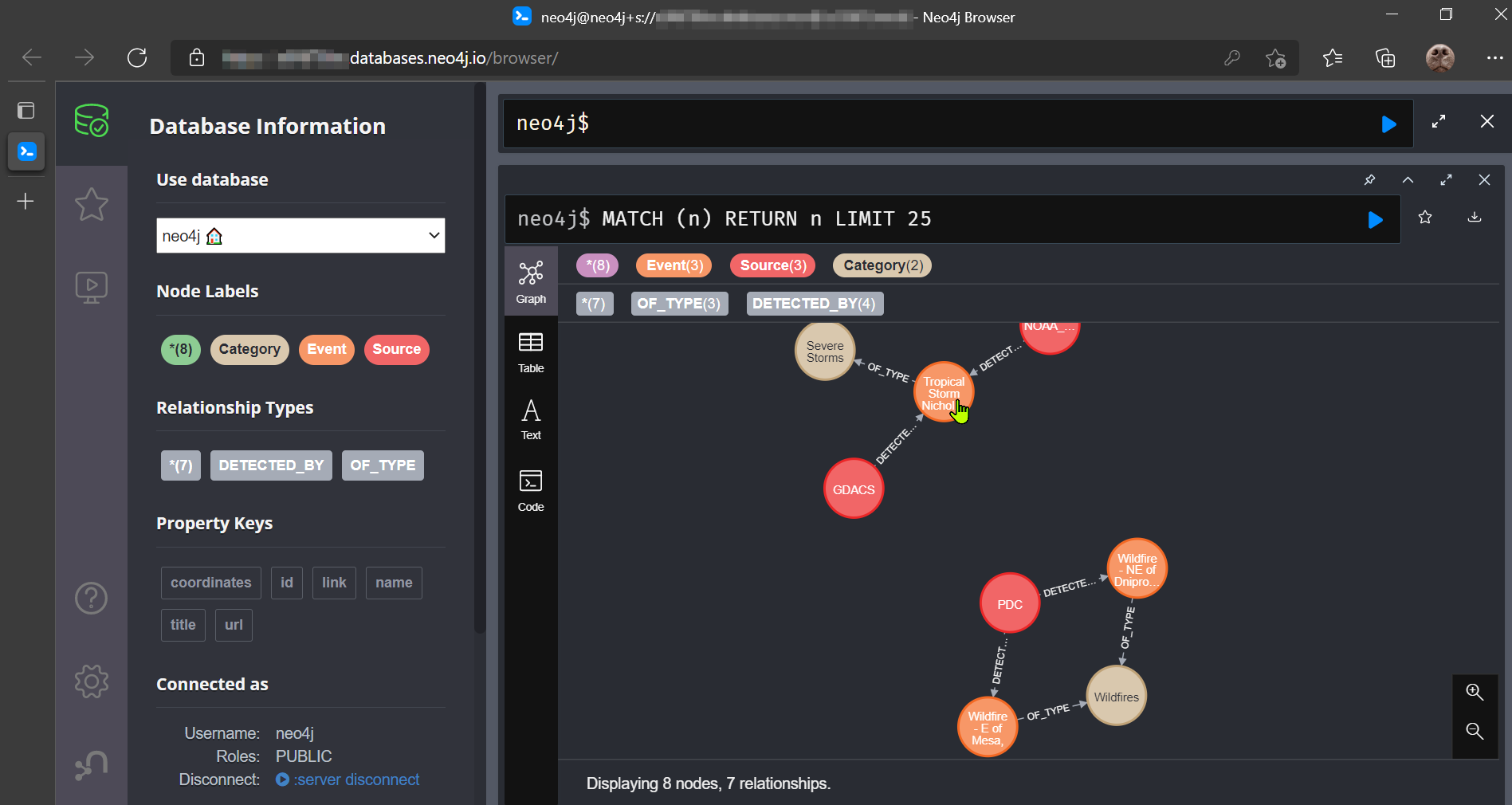
Premable
I recently stumbled upon the fascinating world of property-relationship graphs, and specifically the graph database Neo4J. Graphs’ offer the ability to map relationships and properties across an array of entities, objects, processes and dependencies.
This relationship-centric approach allows one to traverse the graph-space using the richness of the Cypher language enabling performant, intuitive retrieval of information. With this framework one can additionally build rich models which embed semantic knowledge from a domain into a queryable data-store.
Inspiration
This post is heavily inspired by that of William Lyon, check-out his original post for more details on the setup and work-flow. Here I use the publicly available API of the Nasa Earth Observatory Natural Event Tracker to periodically query the endpoint for newly registered storm, wildfire, earthquake, and flood events. In the same call I also compile their associated source and meta-data into a simple graph-model.
Pre-requisites
We need an instance of Neo4j running which can be called from GitHub Actions. Neo4J generously provides free instances to their Aura cloud offering, where you can can started deploying your own instance in a region of your choice. These standard developer instances offer up to 50 0000 nodes, and 175 000 relationships which is more than enough to prototype out your productive-bound use-case or hobby projects.
A GitHub account is also required to deploy your repo and access GitHub Actions.
Lastly you need your favourite API which can deliver some interesting data to be modelled.
Defining the Model
Once you sever is initiated and you have an API in mind, you can call it via the apoc (“Awesome Procedures On Cypher”) library.
call apoc.load.json("https://eonet.sci.gsfc.nasa.gov/api/v3/events?limit=5&days=20&source=InciWeb&status=open")
YIELD valueIn this case I am calling the Events API and passing in some query parameters which returns the following.
{
"link": "https://eonet.sci.gsfc.nasa.gov/api/v3/events",
"description": "Natural events from EONET.",
"title": "EONET Events",
"events": [
{
"sources": [
{
"url": "http://inciweb.nwcg.gov/incident/7835/",
"id": "InciWeb"
}
],
"link": "https://eonet.sci.gsfc.nasa.gov/api/v3/events/EONET_5922",
"description": null,
"closed": null,
"geometry": [
{
"date": "2021-09-07T13:45:00Z",
"coordinates": [
-120.613,
42.277
],
"magnitudeValue": null,
"type": "Point",
"magnitudeUnit": null
}
],
"id": "EONET_5922",
"categories": [
{
"title": "Wildfires",
"id": "wildfires"
}
],
"title": "Cougar Peak Fire"
},
{
"sources": [
{
"url": "http://inciweb.nwcg.gov/incident/7827/",
"id": "InciWeb"
}
],
"link": "https://eonet.sci.gsfc.nasa.gov/api/v3/events/EONET_5911",
"description": null,
"closed": null,
"geometry": [
{
"date": "2021-08-29T16:38:00Z",
"coordinates": [
-123.634,
40.916
],
"magnitudeValue": null,
"type": "Point",
"magnitudeUnit": null
}
],
"id": "EONET_5911",
"categories": [
{
"title": "Wildfires",
"id": "wildfires"
}
],
"title": "Knob Fire"
},
{
"sources": [
{
"url": "http://inciweb.nwcg.gov/incident/7828/",
"id": "InciWeb"
}
],
"link": "https://eonet.sci.gsfc.nasa.gov/api/v3/events/EONET_5909",
"description": null,
"closed": null,
"geometry": [
{
"date": "2021-08-28T12:45:00Z",
"coordinates": [
-117.353,
33.504
],
"magnitudeValue": null,
"type": "Point",
"magnitudeUnit": null
}
],
"id": "EONET_5909",
"categories": [
{
"title": "Wildfires",
"id": "wildfires"
}
],
"title": "Chaparral Fire"
}
]
}We can see that the API returns a nested structure, of which we are interested in the first-level.
One can access the elements within each hierarchy via the UNWIND statement. See the documentation for a explanatory walk-through.
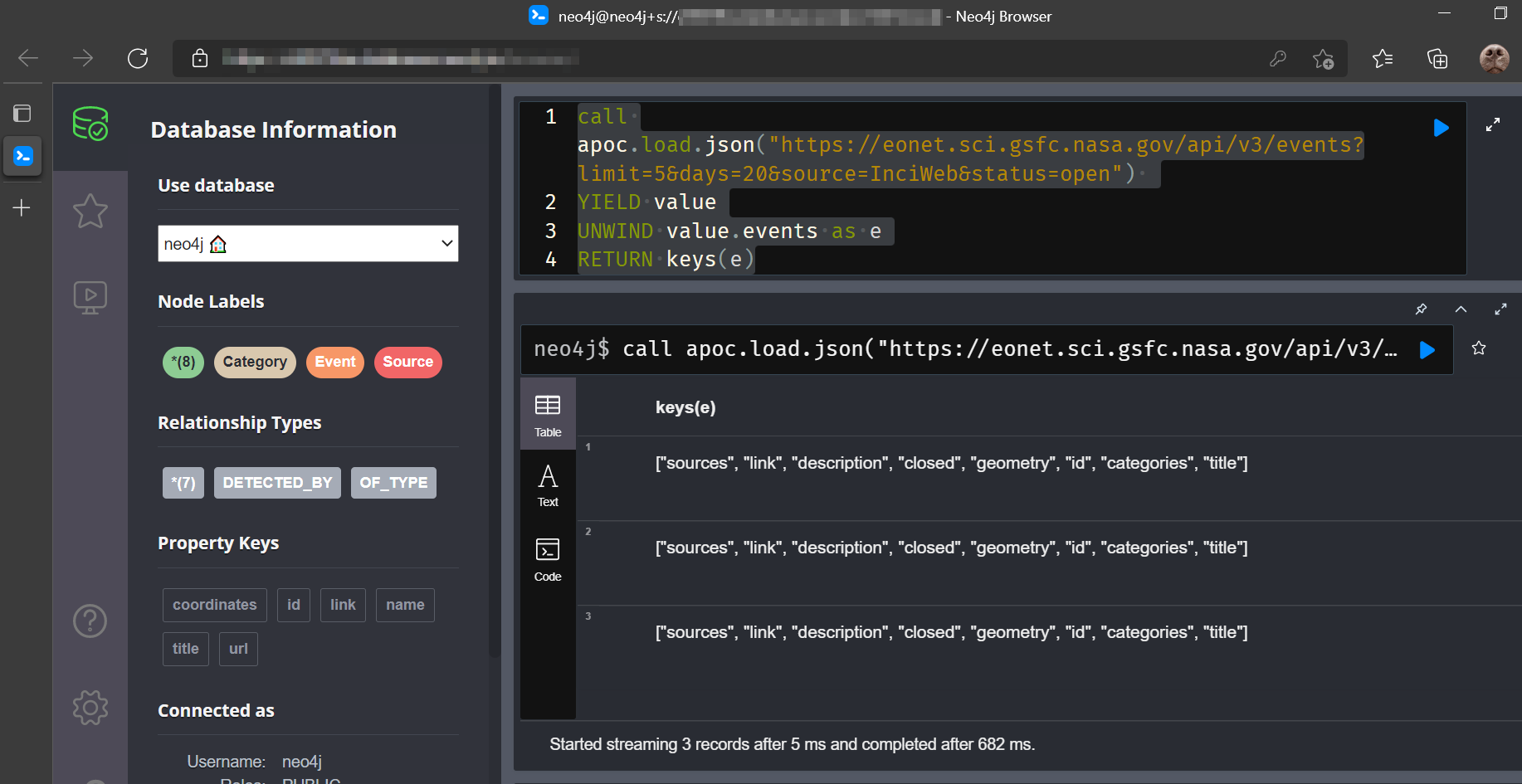
The keys of the appropriate level can be shown as follows.
call apoc.load.json("https://eonet.sci.gsfc.nasa.gov/api/v3/events?limit=5&days=20&source=InciWeb&status=open")
YIELD value
UNWIND value.events as e
RETURN keys(e)Returning…..
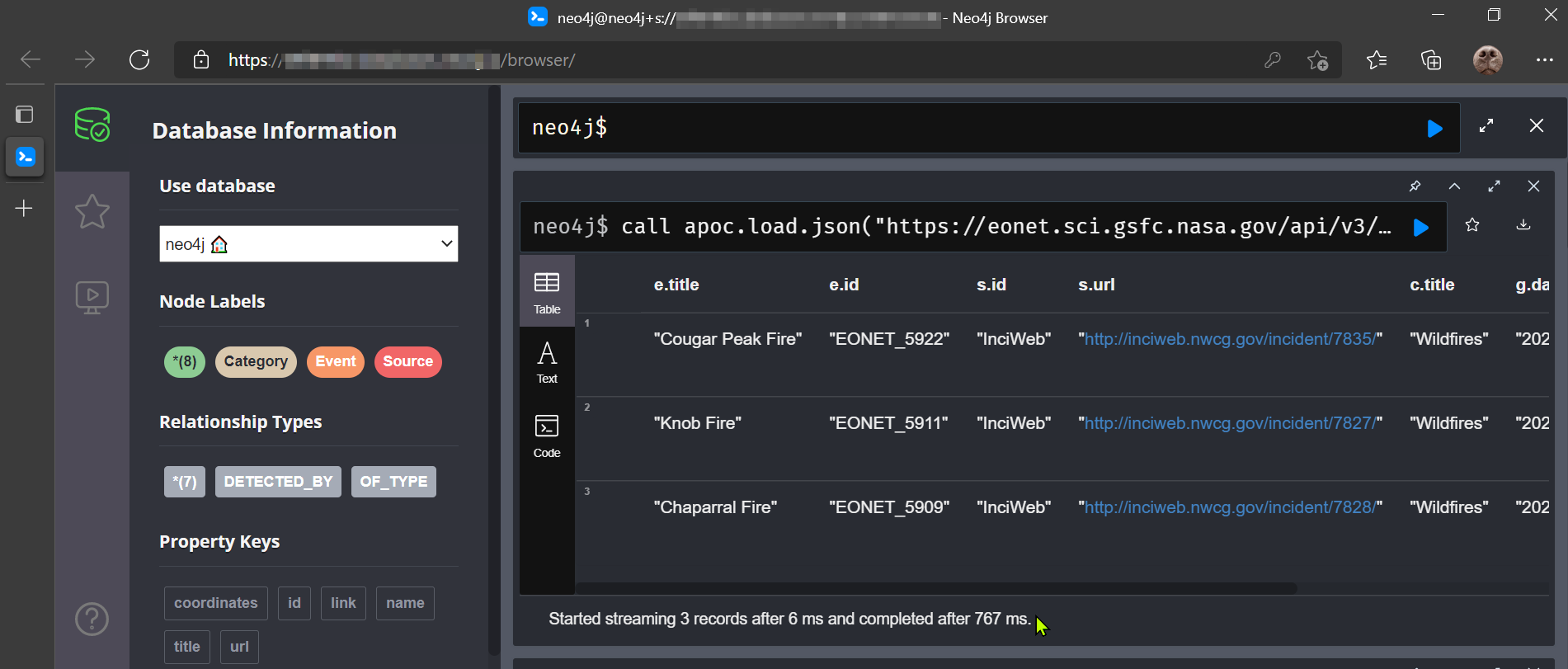
 Some interesting relationships and properties can be retrieved from this object. I would like to have a simple model connecting “Events” to (Event) “Categories”, and associated acquisition data, “Sources”.
Some interesting relationships and properties can be retrieved from this object. I would like to have a simple model connecting “Events” to (Event) “Categories”, and associated acquisition data, “Sources”.
call apoc.load.json("https://eonet.sci.gsfc.nasa.gov/api/v3/events?limit=5&days=20&source=InciWeb&status=open")
YIELD value
UNWIND value.events as e
UNWIND e.sources as s
UNWIND e.categories as c
UNWIND e.geometry as g
RETURN e.title, e.id ,s.id, s.url, c.title, g.date, g.coordinatesReturning…
Insert Data into Neo4J
To load the data into Neo4j and create the respective nodes, relationships and properties a short snippet of Cypher is needed.
call apoc.load.json("https://eonet.sci.gsfc.nasa.gov/api/v3/events?limit=5&days=20&source=InciWeb&status=open")
YIELD value
UNWIND value.events as e
UNWIND e.sources as s
UNWIND e.categories as c
UNWIND e.geometry as g
merge(event:Event {id:e.id}) ON CREATE SET event.title=e.title, event.date = e.date, event.coordinates = g.coordinates
merge (source:Source {name:s.id}) ON CREATE SET source.url = s.url
merge (source)-[:DETECTED_BY]->(event)
merge(category:Category {name:c.title})
merge (category)<-[:OF_TYPE]-(event)
RETURN e.title, e.id ,s.id, s.url, c.title, g.date,g.coordinatesData Retrieval using GitHub Actions
GitHub Actions allows us to define a workflow triggered by Github Events (commits, pull requests, pushes etc.) using either custom code or community published actions. Whist this methodology is often used for CI/CD process, it can also be used as a zero-cost data acquisition and loading mechanism.
Specifically the Flat Data Project aims to simplify the deployment of ETL workflows. The Flat Data Action allows us to schedule a GitHub Action to periodically fetch data via a URL or a SQL statement.
I’ll leave the signing up of GitHub and creating your first repo as an exercise to the reader (still not using GitHub??).
To get started with our GitHub Actions workflow place a new .yml file in the .github/workflows/ folder of your repo.
Give it an appropriate name, and define the steps to run in the Action. In my case the file was defined as below.
name: EONET Data Import
on:
push:
paths:
- .github/workflows/earthobs.yml
workflow_dispatch:
schedule:
- cron: '0 17 * * * *'
jobs:
scheduled:
runs-on: ubuntu-latest
steps:
- name: Check out repo
uses: actions/checkout@v2
- name: Fetch newest
uses: githubocto/flat@v2
with:
http_url: https://eonet.sci.gsfc.nasa.gov/api/v3/events?limit=1&days.json
downloaded_filename: newest.jsonIt’s pretty self-explanatory - you can see I passed in a recurrence schedule using cron (“Everyday at 17:00”) and provide the URL of the endpoint, as well as the destination file. Upon pushing this commit the Action will automatically run and you place an updated json file containing the weather events of the last day into your repo.
Orchestration using the FlatGraph Action
The next step is to expand this workflow to subsequently load the data in your Neo4J instance.
You will need to define a few Repo Secrets to store your database credentials.
- These would be your Neo4j instance username [NEO$J_USER], password [NEO4J_PASSWORD] and the server uri [NEO4J_URI].
The final step is to leverage the Flat Graph GitHub Action. This is a post processing step that enables import into a Neo4J instance using Cypher.
We just need to pass it our above-mentioned credential secrets, and a Cypher query as a parameter and it will reference the data fetched in the previous step.
The final adjusted earthobs.yml file looks as follows.
name: Earth Observation Natural Events Data Import
on:
push:
paths:
- earthobs.yml
workflow_dispatch:
schedule:
- cron: '0 17 * * *'
jobs:
scheduled:
runs-on: ubuntu-latest
steps:
- name: Check out repo
uses: actions/checkout@v2
- name: Fetch newest
uses: githubocto/flat@v2
with:
http_url: https://eonet.sci.gsfc.nasa.gov/api/v3/events?limit=1&days.json
downloaded_filename: newest.json
- name: Neo4j import
uses: johnymontana/flat-graph@v1.2
with:
neo4j-user: ${{secrets.NEO4J_USER}}
neo4j-password: ${{secrets.NEO4J_PASSWORD}}
neo4j-uri: ${{secrets.NEO4J_URI}}
filename: newest.json
cypher-query: >
UNWIND $value.events as e
UNWIND e.sources as s
UNWIND e.categories as c
UNWIND e.geometry as g
merge(event:Event {id:e.id}) ON CREATE SET event.title=e.title, event.date = e.date, event.coordinates = g.coordinates
merge (source:Source {name:s.id}) ON CREATE SET source.url = s.url
merge (source)-[:DETECTED_BY]->(event)
merge(category:Category {name:c.title})
merge (category)<-[:OF_TYPE]-(event) Conclusion
This simple yet powerful architecture yields a flexible approach to collecting interesting data from APIs, modeling them into a graph and handling all of the orchestration and ETL logic with common, free tools!
My Neo4J database is slowly being populated with event data after several days of iteration :D